
Managing AI is Managing Entropy
Every system drifts toward disorder without maintenance. AI specifications are no exception.

Running autonomous coding agents against a living spec means maintaining that spec. The framework we use for that maintenance comes from computational cognitive science, the same field that produced the neural network architectures LLMs are built on. David Marr published his three levels of analysis in 1982 for understanding the visual cortex. We use it to understand what belongs in a specification and what does not.
Our agents land 60+ commits in 60 minutes. Every commit is an opportunity for implementation details to drift into the spec.

How Specs Accumulate Entropy
Agents write back what they discover. A human developer reads a function signature, uses it, and moves on. An agent encounters the same signature and, if the spec tolerates it, adds a reference for future sessions. Over time, a spec grows in token count without growing in behavioral guidance.
Implementation details change on every refactor, every rename, every file move. If those details live in the spec, the spec becomes stale every time the code changes. We only want one copy of any piece of information, and implementation details already have a home in the codebase. At most, the spec should hold a pointer.
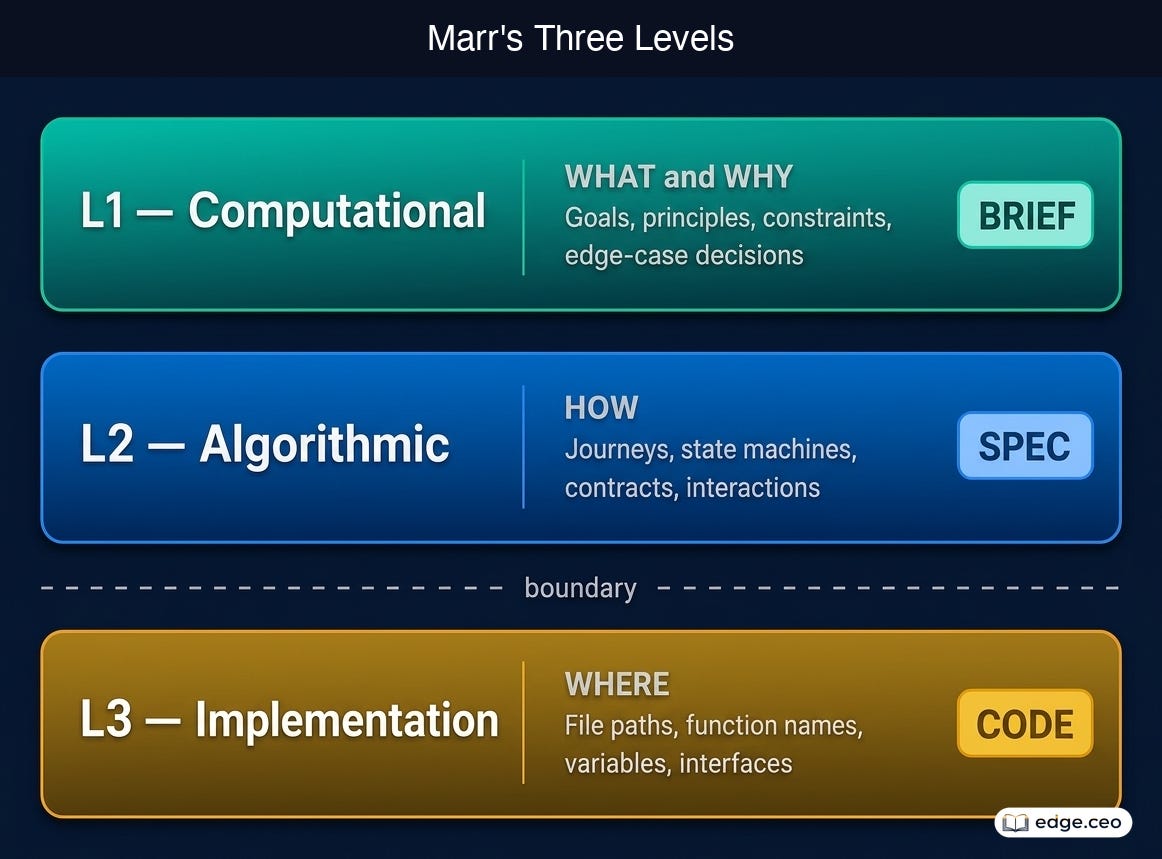
Marr’s Three Levels
Marr proposed that any information-processing system can be understood at three levels. Each level answers a different question:
L1, Computational. What the system does and why it exists. Goals, principles, constraints, edge-case decisions. This is the most stable layer and changes only when the mission changes.
L2, Algorithmic. How the system achieves its goals. Customer journeys, state machines, interaction patterns, cross-module contracts, data representations. It changes when the approach changes.
L3, Implementation. Where in the codebase the procedure runs. File paths, function names, component interfaces, variable assignments. It is the least stable layer, changing whenever code is reorganized. It should never be duplicated into the spec because duplication means drift.
The question that separates L1/L2 from L3: “Will this still be true after the next refactor?” If yes, it belongs in the spec. If no, it belongs in the codebase.
What We Found Works
Our spec had grown to 325,000 tokens. The agents were productive and the architecture was sound, but the spec consumed most of a million-token context window and left no room for working conversations.
We went sentence by sentence. Does this describe what the system does (L1), how it achieves it (L2), or where in code it lives (L3)? L1 and L2 stayed. L3 went back to the codebase. The result was a 48 percent reduction, from 325,000 tokens down to 170,000, without losing a single goal, principle, journey, or contract. The agents loaded the smaller spec and continued without regression. We codified the framework in the same commit and it became the maintenance standard going forward.

How We Use It
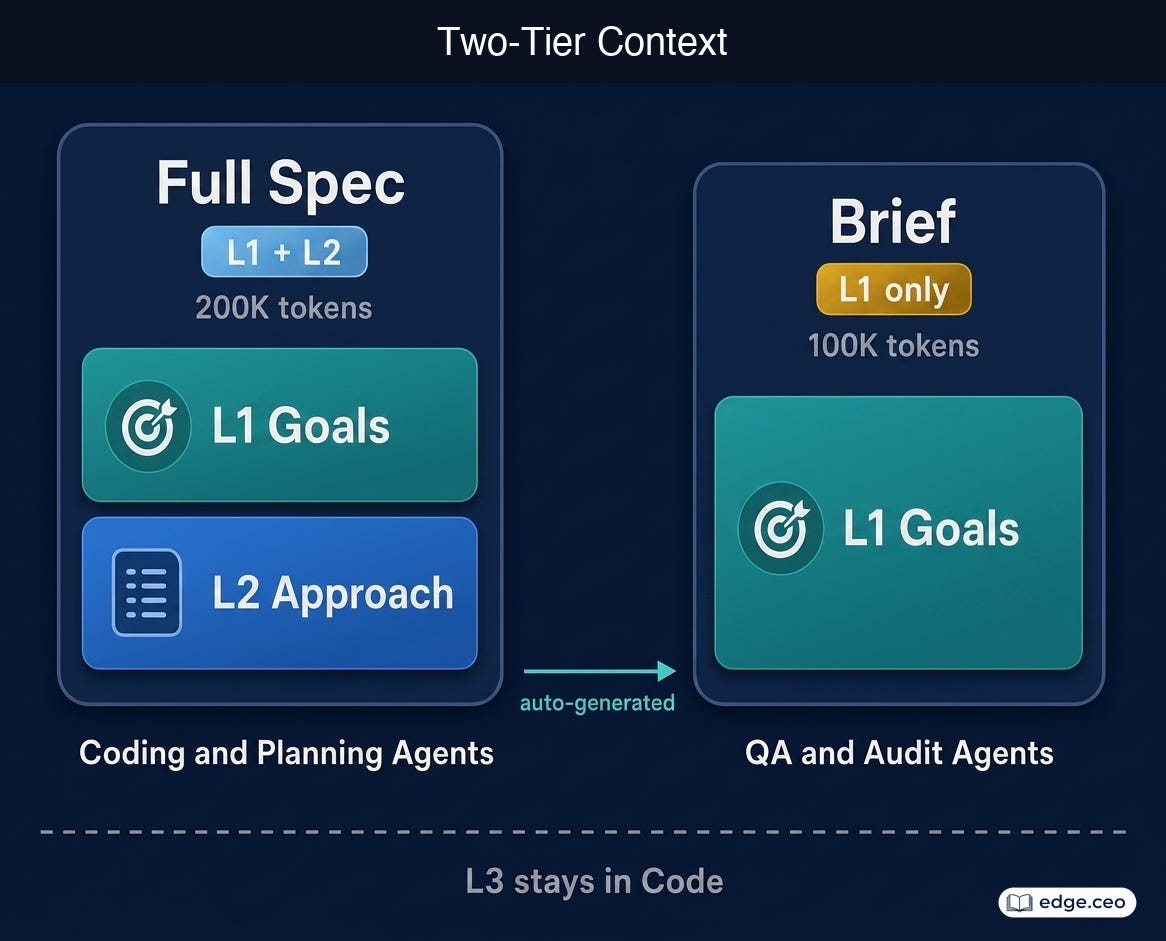
Humans specify the goals (L1), and humans and AI align on approach (L2), usually through conversation. Implementation (L3) stays in the code. This maps naturally to how much context different agents need.
QA and audit agents run with L1 context only, which we call the Brief. They need to know what the system should do and verify it does. Coding and planning agents run with L1 and L2 context, which we call the Spec. They need both the goals and the approach to build the right thing the right way.
We generate briefs from the full spec automatically. CI enforces freshness. An agent working from the brief cannot accumulate L3 content because the files it works with do not contain L3 content. The ceiling is structural, not instructional.
If a goal or approach changes, we update the spec and the briefs regenerate. If an implementation detail changes, nothing in the spec needs updating because it was never there. That asymmetry is the point.
Gardening
Keeping a spec clean is gardening. The garden grows from productive work, and the weeds are implementation details that accumulate because agents are helpful and concrete. Marr’s three levels make the weeding mechanical rather than subjective.
The discipline is routine. After every batch of agent work, we look at what grew and ask whether it describes what the system does or where in code it lives. What does not belong goes back. The spec stays at L1 and L2, the code stays at L3, each with one copy in one place, maintained continuously.
Managing AI is managing entropy.