
Introducing SPEAR: The Management Framework for AI
The strong-start-weak-finish problem in AI is a process problem, not a model problem.

Many years ago my PMs came to me asking to skip steps in the product process so they could move faster. They had a really long roadmap and wanted to cut steps that “felt like overhead.” My answer was no, but not for the reason they expected. I told them not to skip steps, but to go through the same process in 30 minutes instead of 30 days.
Quality falls the moment a step is skipped, and I had watched it happen too many times. When we skipped mapping out the wireframes, we shipped the wrong experience and had to redesign it after launch. When we skipped looking at the data, we fixed the wrong bottleneck and the funnel did not move. The skipped step never disappear. It turns into rework that is later paid back later with interest.
The same lesson applies to AI. The temptation to skip steps and just let the assistant execute is real, and the cost shows up the same way. The fix is not to skip steps. It is to do all five steps in seconds, every time. That is where SPEAR comes in.
The five phases
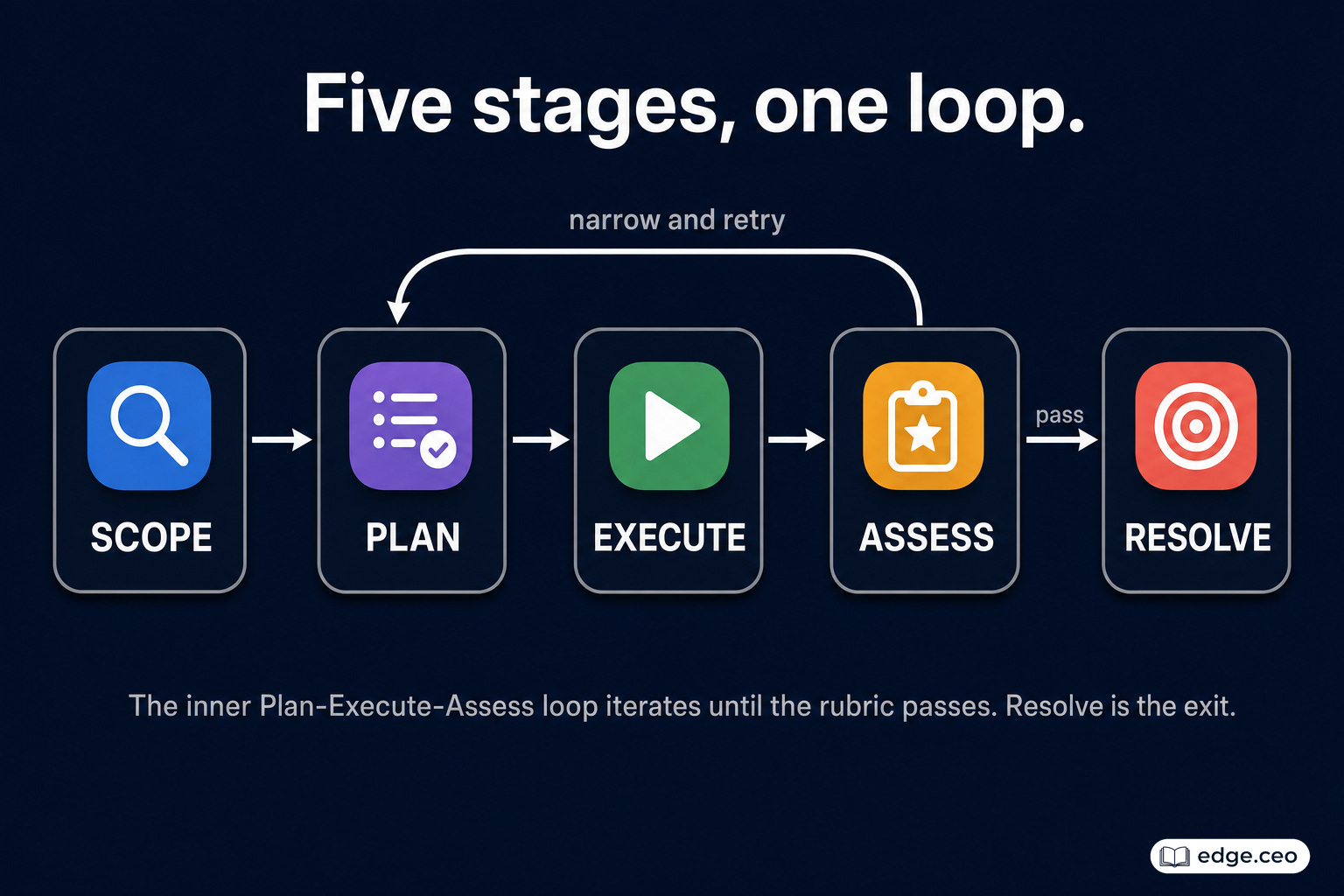
The five phases of standard project management hold whether the project lasts five months or five seconds. They are initiate, plan, execute, monitor, and close. SPEAR adjusts them for the software factory: Scope, Plan, Execute, Assess, Resolve.
Each phase is a gate, not a checkbox. Scope passes when ambiguity has been surfaced and resolved. Plan passes when an ordered sequence is visible and approved. Execute passes when the work completes.
Assess is where SPEAR turns into a self-correcting loop. It scores the result against the original scope and plan, and reviews the work product against a rubric. When all three are aligned, the run advances to Resolve.
When it is not, the run returns to Plan. The Plan is narrowed to the gap that Assess found, Execute runs again, and Assess scores again. This inner Plan-Execute-Assess cycle repeats until the result holds up. Resolve is the exit. It closes out the run after Assess passes and nothing is left to fix.
Why five, not three
A lot of assistants already do some version of Scope, Execute, and Resolve. Plan and Assess are the two phases that get dropped because they feel like overhead. They are not.
Without Plan, the assistant moves too quickly and executes incoherently because the assistant assumed too much. The cost is irreversible mistakes that show up later as support tickets and manual cleanup. Plan is also what makes the sequence visible before the assistant acts, so a wrong assumption can be caught early instead of paid for later.
Without Assess, the assistant produces work that it thinks is finished but is not, usually something that’s not MECE (see below). The user catches the gap later, and at that point they are doing QA for the AI. That is the moment where agentic coding becomes frustrating.
The cost of adding Plan and Assess to a run is two or three seconds, less than the time the assistant already takes to respond. The savings are the cleanup time you no longer have to do yourself, and the rework you no longer have to pay for later. The same trade my PMs faced applies here, compressed by orders of magnitude.

Designing the assess rubric
Assess is what most assistants skip, and it matters most. It also needs the most design. Without a rubric, assess collapses into “looks good to me.” The assistant declares itself done, and nothing forces it to be honest. The rubric is the part of SPEAR that has to be written down.
A rubric works when it is MECE — mutually exclusive and collectively exhaustive. Mutually exclusive means rubric items do not overlap (i.e. linearly separable), so a failure on one item is independent from another. Collectively exhaustive means the rubric covers every dimension that has to pass, so the assistant cannot quietly pass a missing one. Overlap creates drift. Gaps create false positives.
Visual QA is a useful example because the failure modes are concrete and observable. Below is an illustrative checklist, but I recommend you have Claude generate a better one:

It scores each pillar from 1/10 and anything that’s not an 10 is considered a fail. The same MECE structure holds for any artifact a loop has to converge on.
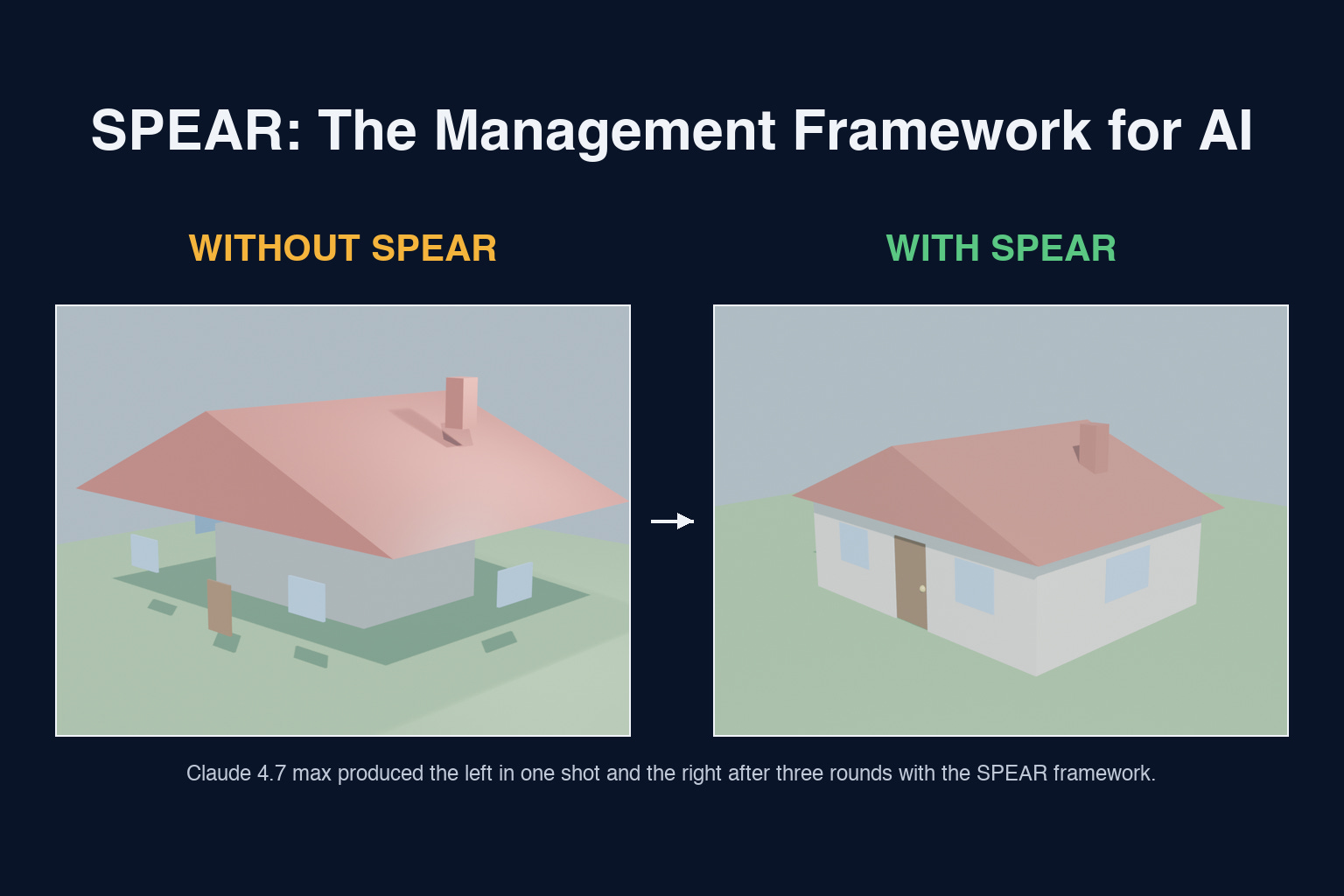
I tested SPEAR on a 3D house generation with Claude 4.7 max: once zero-shot, once through SPEAR. For the SPEAR run, the assessment rubric ran the model through standard architectural views (top-down, front, side, perspective) and scored each view.
The zero-shot output had windows floating beside the walls, a door lying flat on the ground, and a chimney that barely anchored through the roof. With SPEAR, the same model ran for three rounds, with each assess pass asked to be more critical than the last: round one demanded every element attach to the building; round two, that proportions match real architecture; round three, that nothing in the model float, clip, or sit in space. The rubric got more critical each round, and the model got better each round.
What changes in practice
The shift is small, but the change in outcome is large. SPEAR adds only two or three seconds to each AI run, no meaningful slowdown and saves you a ton of time in QA.
It checks itself against a rubric and narrows the gap, round by round, until the gap closes. That is how it turns a vibe into a production-ready component.
The same loop scales beyond seconds. I have run it for minutes on a 3D model, an hour on a coding task, and twenty-four hours on a large workstream. Same five phases, only the clock changes.
SPEAR gives models the structure to succeed, a rubric to check against, and a loop to optimize until the rubric passes. We use this every day, and I cannot fully picture how much it will change the way we work.
Same management. Different worker.